 xyhao's Blog
xyhao's Blog

小林coding那边已经很详细了,这里我只对一些比较重要的点和不太懂的地方做出补充 小林Coding/Redis
更多博客请见 我的语雀知识库
AOF
介绍
AOF是将kv以命令的形式保存在缓存区。缓存区的数据会被追加到AOF文件中,每秒一次
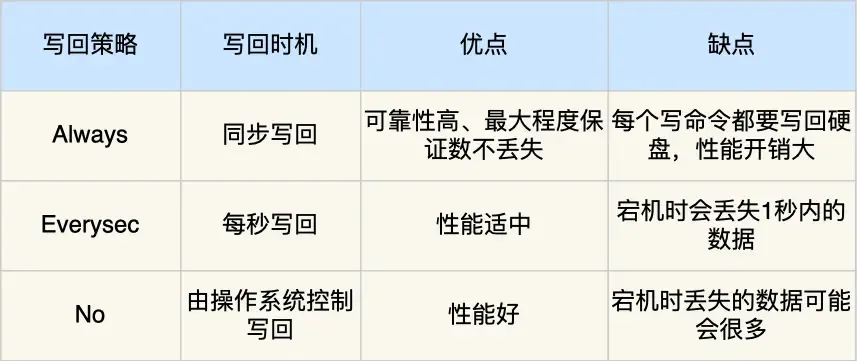
三种刷盘策略
每次新增kv时,先执行写命令,再把kv保存到AOF缓存区,比起先保存到缓存区再执行写命令,这样做的好处是如果命令执行不成功,就不需要去修改缓冲区或者磁盘的AOF文件了。 那么缓存区的数据何时被刷盘呢?
- 每次执行写命令后就刷盘,这样做性能不好
- 不去管刷盘,把刷盘的时机交给操作系统决定。这样做会丢失不定量的数据
- 每隔一秒或者一个固定的时间,刷盘。相比于前两种,这是折中的方案。
重写
随着程序的运行,总有一些kv被反复修改过。那么这条kv每次被修改的命令都会被保存,但只有最后的命令才有效。所以缓解AOF文件体积庞大的着手点就是每条kv只保存最后的命令。 完整过程:
-
创建一个新的空的AOF文件
为什么不复用现有的AOF文件?重写失败了那这个文件就被污染了
-
主进程fork出一个子进程,子进程通过复制父进程的页表可以共享父进程的内存,节约内存。
为什么不是创建一个线程?线程之间共享的内存,所有线程都有写权限。势必会引发并发问题,需要加锁解决。而父子进程之间共享内存,两进程都只有读权限,执行写命令的话会触发写时复制
-
读取redis的所有kv,将每条kv以命令的形式保存在新的AOF文件中。
如果在此期间,主进程对共享内存执行了写操作,那么被该写操作影响的内存会被复制一份,写操作的内存对象变成了复制后的内存。原来的内存供其他进程接着使用。
- 主进程把AOF持久化期间执行的写命令保存在缓存区。
- 新的AOF文件接着读取主进程缓存区的数据写入。完成后覆盖原有AOF文件。AOF重写过程结束。
什么是写时复制? 写时复制是一种优化策略,主要用于操作系统和编程语言中,以减少不必要的数据复制,从而提高效率和节省内存。其工作原理如下:
- 当多个进程或线程需要访问相同的资源(如内存页或文件)时,它们共享同一份资源。
- 只有当其中一个进程或线程尝试修改资源时,系统才会为这个特定的进程或线程创建资源的一份副本,并且只修改副本,而原始资源保持不变,供其他进程或线程继续共享。
- 这种机制可以显著减少内存的使用,尤其是在处理大量相同数据的场景下,比如在虚拟化环境中或在多进程共享大量相同代码和数据的应用中。
另外,写时复制的时候会出现这么个极端的情况。 在 Redis 执行 RDB 持久化期间,刚 fork 时,主进程和子进程共享同一物理内存,但是途中主进程处理了写操作,修改了共享内存,于是当前被修改的数据的物理内存就会被复制一份。 那么极端情况下,如果所有的共享内存都被修改,则此时的内存占用是原先的 2 倍。 所以,针对写操作多的场景,我们要留意下快照过程中内存的变化,防止内存被占满了。

RDB
介绍
对于一条kv,AOF记录它的方式是记录创建它的命令。而RDB则是记录这条kv本身。 Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave,他们的区别就在于是否在「主线程」里执行:
- 执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,会阻塞主线程;
- 执行了 bgsave 命令,会创建一个子进程来生成 RDB 文件,这样可以避免主线程的阻塞;
RDB快照是全量快照,也就是说每次执行快照,都是把内存中的「所有数据」都记录到磁盘中。这是一个非常“重”的操作。对redis服务器有一些性能上的影响。因此RDB的刷盘不能像AOF那样频繁(AOF将缓存区的数据追加到AOF文件中,每秒一次)。 因此通常RDB每隔几分钟才会执行一次,一旦服务器宕机,RDB比AOF丢失的数据更多。
子进程与写时复制
参考上文AOF部分对子进程与写时复制的介绍。 在执行RDB复制时,由于子进程和写时复制的原因,redis服务器依然能够对外提供服务。执行RDB快照的子进程是对复制过后的内存操作的,不影响父进程。
但是fork子进程的过程会短暂的阻塞父进程。因为需要复制父进程的页表给子进程。
RDB子进程复制与写时复制的缺陷
在保存数据期间主进程写入的数据会以写时复制的形式保存在内存里。不会被本次的RDB给持久化。 如果系统恰好在 RDB 快照文件创建完毕后崩溃了,那么 Redis 将会丢失主线程在快照期间修改的数据。
为什么AOF不会有这个问题?
因为持久化期间主进程执行的写命令被置入了缓冲区。子进程也会读取这个缓冲区的数据。
为什么RDB不仿照AOF解决这个问题?
不是解决不了,而是这样做不符合RDB的设计理念。 RDB的目的是保存某一时间点的所有数据的快照。关键在于,某个时间点。发生在这个时间点后的数据不归RDB管。
RDB与AOF的对比与混合使用
RDB优点:
由于RDB保存的kv数据本身,恢复数据就会比AOF快不少(AOF要把所有命令执行一遍)。
AOF优点:
AOF由于秒级刷盘的策略,服务器宕机丢失的数据比RDB少得多。在Always刷盘策略下,甚至不会丢失数据。
能不能集两者优点与一身呢?
RDB与AOF合体使用
redis.conf文件中有一条设置:
aof-use-rdb-preamble yes
开启后,会以混合持久化的形式保证数据持久化。这样就使得持久化期间的新增的数据也会被持久化。
当开启了混合持久化时,在 AOF 重写日志时,fork 出来的重写子进程会先将与主线程共享的内存数据以 RDB 方式写入到 AOF 文件,然后主线程处理的操作命令会被记录在重写缓冲区里,重写缓冲区里的增量命令会以 AOF 方式写入到 AOF 文件,写入完成后通知主进程将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的的 AOF 文件。
也就是说,使用了混合持久化,AOF 文件的前半部分是 RDB 格式的全量数据,后半部分是 AOF 格式的增量数据。

这样的好处在于,重启 Redis 加载数据的时候,由于前半部分是 RDB 内容,这样加载的时候速度会很快。
加载完 RDB 的内容后,才会加载后半部分的 AOF 内容,这里的内容是 Redis 后台子进程重写 AOF 期间,主线程处理的操作命令,可以使得数据更少的丢失。