 xyhao's Blog
xyhao's Blog

更多博客请见 我的语雀知识库
Kafka的事务由Broker的事务协调器负责,也有ACID特性。但一致性由于CAP限制只保证最终一致性且隔离级别只有读未提交和读已提交
示例代码
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// 3 初始化事务
producer.initTransactions();
// 4 标识事务开始
producer.beginTransaction();
try {
// 5 构建待发送的消息
ProducerRecord<String, String> record = null;
for (int i = 0; i < 20; i ++) {
record = new ProducerRecord<>(topicName, msg);
// 6 发送消息
producer.send(record);
// 省略一些其他逻辑
}
// 7 commit事务
producer.commitTransaction();
} catch (ProducerFencedException e1) {
e1.printStackTrace();
producer.close();
} catch (KafkaException e2) {
e2.printStackTrace();
producer.abortTransaction();
}
// 8 关闭生产者实例
producer.close();
}
事务执行原理
初始化事务
- 首先,需要在生产者客户端配置 producerProps.put(“transactional.id”, “ShiWuID”);,设置 事务id,可以让程序重启之后被识别为同一个事务生产者。
- 当执行
producer.initTransactions()后,生产者会与某个Broker端的事务协调器产生联系。具体怎么确定是哪个Broker呢?- 在 Kafka 中有个特殊的事务 topic,名称为 __transaction_state ,负责持久化事务消息。该 topic 默认有 50 个Partition,每个Parition负责一部分事务。
- 事务划分规则是当生产者向 bootstrap.servers 中任何一个地址发送请求时,该 Broker 会先计算 事务id 的哈希值,然后将该哈希值 % 50 得到一个计算结果,该结果就是 __transaction_state 的某个Partition
- 由该分区的 Leader 副本所在的 Broker 节点就是该生产者所属的事务协调器。随后就会向生产者反馈事务协调器的地址
发送消息
生产者在每次发送消息的请求中都会包含 PID、Epoch 和 事务id 以及其他字段。而生产者在每次调用 producer.send() 方法时,需要循环执行以下两个步骤:
- AddPartitionsToTxnRequest:将本次发送请求涉及到的 TopicPartition 添加到事务协调器对应的 __transaction_state 的某个分区中,这样当事务提交之后,事务协调器会将 __transaction_state 分区中 TopicPartition 的状态标记为已提交(Commit)或放弃(Abort)。
- ProduceRequest:对于每个 PID、Epoch 和 事务id 组合,生产者都会维护一个序列号,该序列号从 0 开始,每条消息的序列号都会单调递增。Broker也会维护每个 PID、Epoch 和 Transactional ID 组合的序列号,如果当前序列号不比前一个序列号大 1,就会拒绝请求。
提交事务
根据事务的原子性,要么全部成功,要么全部回滚。生产者就会向事务协调器调用 commitTransaction() 或 abortTransaction(),从而完成事务。
消费者消费
以下两次调用是消费者端的事务一致性功能
- AddOffsetsToTxnRequest:消费者会通过 AddOffsetsToTxnRequest 将 Consumer Group ID 信息传递给事务协调器,事务协调器从中提炼出消费者订阅的 TopicPartition,并将其记录在事务日志中。
- TxnOffsetCommitRequest:当消费者成功消费完数据之后,会在内部通过调用 TxnOffsetCommitRequest,将该 TopicPartition 和 消息 offset 的写到 __consumer_offsets 主题中,表示数据已经成功消费。注意,在生产者发送消息的事务完成之前,消费者是无法看到这些消息的 offset 的。即当消费者将隔离级别设置为isolation.level = read_committed时,消费者看不见未完成状态的消息,只能看见事务已提交状态的消息。
事务协调器解决数据不一致问题
先举个例子:生产者向topic1发送两条消息。下游消费者等待事务提交后消费这两条消息 整体执行流程如下:
- 生产者开启事务,锁定事务协调器
- 向topic1的Partition1发送两条消息,同时向事务协调器发送topic1,事务协调器记录topic1的Partition1参与了该事务。事务协调器还会向__transaction_state这个topic里写入一条控制消息,记录这条消息所属的事务id。
- 事务协调器维护topic1的Partition1的LSO(log stable offset)。一个Partition中存了多个事务消息,也存储了很多非事务的普通消息,而LSO为第一个正在进行中的事务消息的offset。
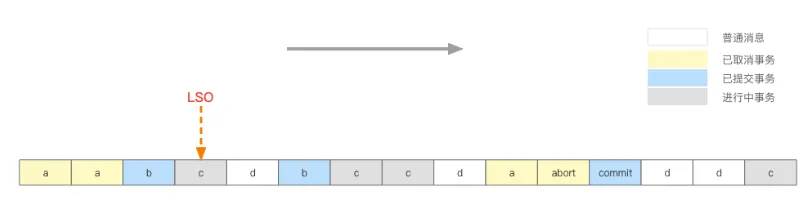
如上图:
a: 已经无效的事务
b: 已经提交的事务
c: 正在进行中的事务(不确定最终是取消还是提交)
d: 普通消息,非事务消息
在LSO之后的位置(上图LSO右边)的消息是不可以被隔离级别为读已提交的消费者消费的
- 生产者提交事务,向事务协调器发送信号,事务协调器修改事务状态的同时,通知本次事务涉及到的所有Partition更新LSO。
- 生产者主动回滚事务或触发超时,事务协调器主动回滚事务。事务协调器通知各个partiton更新LSO并将本次事务产生的消息作废。
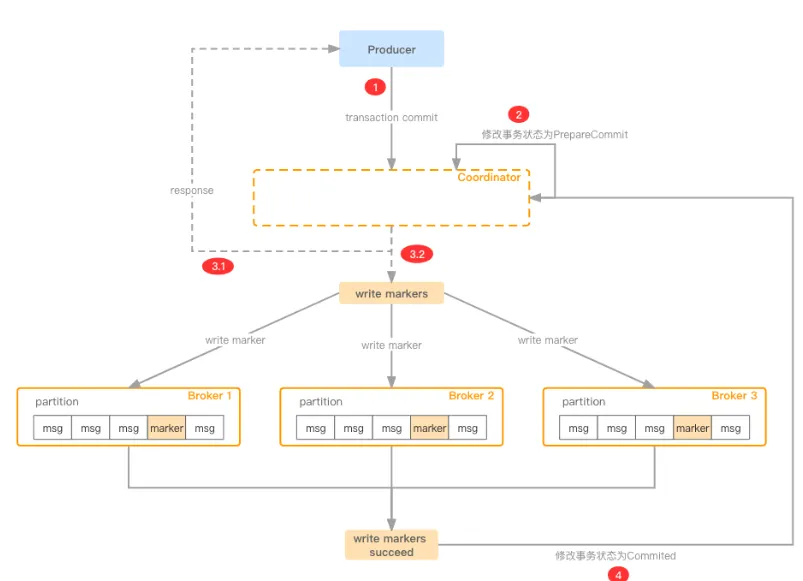
Kafka事务的整体流程是分布式事务里标准的两阶段提交
分布式事务
跨会话和跨 Partition 的幂等性
- 跨会话幂等性:
Kafka 的事务机制保证了即使在生产者会话之间切换,基于相同事务 ID 的操作仍然保持幂等性。如果生产者崩溃并重启,只要事务 ID 是相同的,Kafka 会确保不会重复处理同一事务的消息。
- 跨 Partition 幂等性:
Kafka 的事务机制允许生产者在多个 Topic 和分区中发送消息,并通过事务 ID 维护幂等性。即使消息分布在多个分区中,Kafka 会确保所有相关的消息在事务提交前不会被重复写入或丢失。
一些细节
-
问题1: 上图3.1向
__transaction_state主题写完事务状态后,便给Producer回应说事务提交成功,假如说3.2执行过程中被hang住了,在Producer看来,既然事务已经提交成功,为什么还是读不到对应消息呢?- 的确是这样,这里成功指的是Coordinator收到了消息,并且成功修改了事务状态。因此返回成功的语义指的是一阶段提交成功,因为后续向各个Partition发送写marker的会无限重试,直至成功
-
问题2: 上图3.2中向多个Broker发送marker消息,如果Broker1、Broker2均写入成功了,但是Broker3因为网络抖动,Coordinator还在重试,那么此时Broker1、Broker2上的消息对Consumer来说已经可见了,但是Broker3上的消息还是看不到,这不就不符合事务语义了吗?
- 事实确实如此,所以kafka的事务不能保证强一致性,并不是说kafka做的不够完美,而是这种分布式事务统一存在类似的问题,CAP铁律限制,这里只能做到最终一致性了。不过对于常规的场景这里已经够用了,Coordinator会不遗余力的重试,直至成功
-
问题3:LSO之前有3条消息,2个a(事务取消),1个b(事务提交),consumer读到这3条消息后怎么处理呢?无非就是以下两种处理逻辑。
- 暂存在consumer端,直至读取到事务最终状态,再来判断是吐给业务端(事务成功),还是消息扔掉(事务取消)
- 这样设计是没有问题的,可以保证消息的准确性,但是如果某个事务提交的数据量巨大(事务最长超时时间可达15分钟),这样势必造成consumer端内存吃紧,甚至OOM
- 实时判断当前消息是该成功消费还是被扔掉
- 能够实时判断肯定是非常理想的结果,可是如何实时判断呢?难道每次消费时都要再向broker发送请求获取消息的状态吗?
- Kafka具体采用哪种策略?
实际上Partition依托于__transaction_state主题里的控制消息,是可以得知消息状态的。Partiton 会根据LSO和事务日志的记录,只返回已提交的消息。消费者不需要查询或额外判断消息的状态 。
- 暂存在consumer端,直至读取到事务最终状态,再来判断是吐给业务端(事务成功),还是消息扔掉(事务取消)