 xyhao's Blog
xyhao's Blog
更多博客请见 我的语雀知识库
链表成环
这个问题是JDK7中put方法是头插法导致的
JDK8及后续版本已经改成尾插法修复此问题
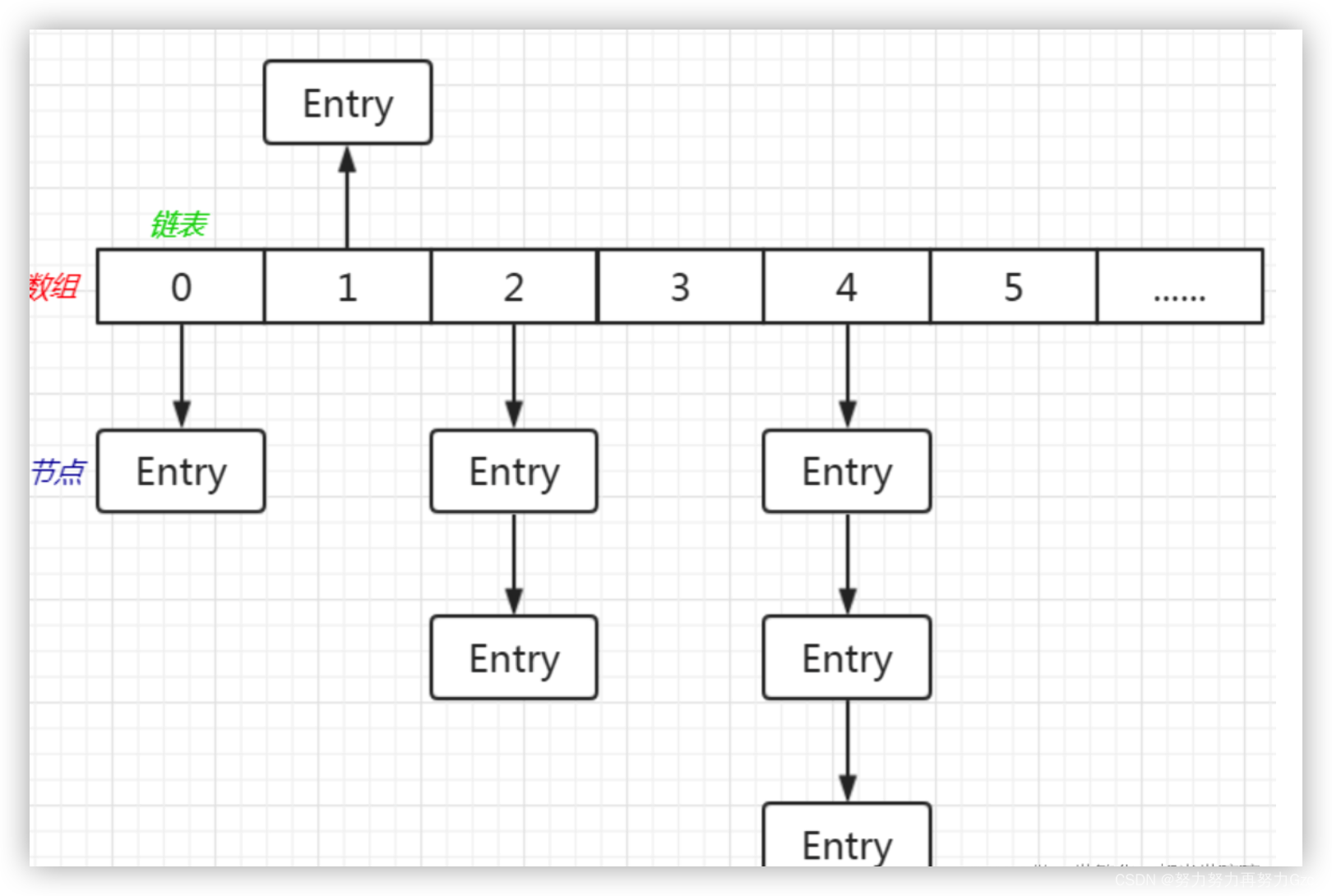
哈希表成环
数据丢失
共有两种数据丢失的位置:
-
table[i]为null时的哈希桶头部
有两个线程:B插入(2,”two”),A插入(1,”one”)。
假如table[15]这个哈希桶是null,A和B并发执行中都知道15是null
B先执行,tab[15] = new node(hash, 2,”two”, null)
A后执行,tab[15] = new node(hash, 1,”one”, null)
正常来说应该是
tab[15] = new node(hash, 2,”two”, null)
tab[15].next = new node(hash, 1, “one”, null)
但实际是
tab[15] = new node(hash, 1, “one”, null)
tab[15].next = null
但是A把B put 的数据覆盖了。get(2)是get不到的 -
table[i]不为null时的哈希桶尾部
看下面源码就知道其实和前一种情况是一样的
结合源码看看:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // A和B都运行到这里,但是A时间片用尽,B先执行
/*
table[i]为null时数据丢失问题
B先执行,tab[15] = new node(hash, 2,"two", null);
A后执行,tab[15] = new node(hash, 1,"one", null);
完美把B覆盖了
这里的并发问题是加锁 && 加判断解决的
*/
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
//下面这行也会出现并发问题,这个并发问题加锁直接解决了
if ((e = p.next) == null) {
/*
table[i]不为null时数据丢失问题
B先执行,p.next = new node(hash, 2,"two", null);
A后执行,p.next = new node(hash, 1,"one", null);
完美把B覆盖了
*/
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
解决方案
如何解决?
加锁。
看看ConcurrentHashMap的源码是怎么做的(JDK21)
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
// 整个表都为null
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 要插入的桶为null,就通过cas插入
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
// 这个桶正在迁移,执行helpTransfer帮助其迁移
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
/*
onlyIfAbsent是boolean类型。true表示仅在键不存在时put,否则不put
fh == hash表示是否出现哈希碰撞
(fk = f.key) == key || (fk != null && key.equals(fk))
检查当前节点的键(fk)是否与插入元素的键相同。如果键相同,则表示当前桶中已经存在这个键。
也就是说,如果
只在不存在key重复时才put
并且 出现了哈希碰撞
并且 哈希桶的头节点的key和待插入元素的key相同
并且 头节点的value不是null
那么就返回头节点,不插入
*/
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
/*
解决table[i]为null时头部数据丢失的问题
铁了心要插入,就执行下面的代码
先锁住哈希桶头节点
顺着头节点往下遍历
如果出现了key相同的节点并且onlyIfAbsent = false(已经存在key也插入,覆盖掉)
遍历完了还没有出现key相同的节点,就新建一个节点加到链表尾部,也就是尾插法
防止并发问题的关键代码是哪一行呢?
synchronized (f) {
if (tabAt(tab, i) == f) 是加锁后的这一行
还是以上文的AB两个线程举例
现在tabAt(tab, i) = null, f = tabAt(tab, i) = null
A和B都执行到了synchronized这里,竞争锁
B竞争成功,此时语句if (tabAt(tab, i) == f) 成立,开始插入
tabAt(tab, i) = tab[i] = new node(hash, 2,"two", null);
然后B释放锁,A得到锁
A执行语句if (tabAt(tab, i) == f)
发现结果为false。tabAt(tab, i)不是null,是node(hash, 2,"two", null)
于是A不再插入
*/
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
/*
table[i]不为null时
下面这行不可能出现并发问题
由于锁的原因
后执行的A线程执行到此处时一定已经遍历过了B线程put的节点
不会再出现key不同也覆盖的情况
*/
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
顺便吐槽一下源码的代码风格,在判断语句里给变量赋值,给我整懵了。
直接看最后一个else的时候发现变量怎么定义了没赋值?仔细一看原来是在判断语句里赋值。
太恶心了,就不能在定义时就赋值吗?