 xyhao's Blog
xyhao's Blog

小林coding那边已经很详细了,这里我只对一些比较重要的点和不太懂的地方做出补充 小林Coding/Redis
更多博客请见 我的语雀知识库
分摊主服务器的压力
在主服务器和从服务器同步数据期间,如果从服务器数量非常多,那么传输RDB文件会大大占据主服务器的网络带宽,影响服务。所以从服务器不必是主服务器的从服务器,也可以是从服务器的从服务器,如下图:
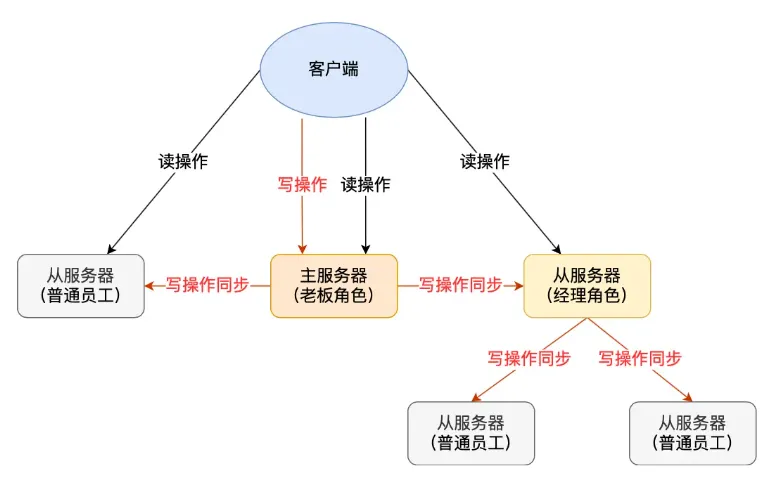 主服务器只把RDB文件传给少量的从服务器,这些从服务器再把RDB文件传给其他的从服务器。这样就大大减少了数据同步对主服务器的影响。
主服务器只把RDB文件传给少量的从服务器,这些从服务器再把RDB文件传给其他的从服务器。这样就大大减少了数据同步对主服务器的影响。
增量复制
如果从服务器网络阻塞,导致数据没有被及时同步。又该如何保持主从之间数据的一致性呢? 重新传输一遍全量的RDB文件吗?太低效了。
Redis是这样做的: 从服务器网络正常后发送增量复制的信号给主服务器,主服务器把从服务器断线期间的写命令发给从服务器。 问题在于,主服务器怎么知道哪些写命令发生在这个从服务器断线期间的?
redis服务器有一个叫repl_backlog_buffer的缓冲区。所有的写命令都会被记录在这个缓冲区里。并维护一个偏移量用于标记当前最新的写命令的偏移量。
从服务器重连后把自己的偏移量发给主服务器。主服务器就可以根据双方的偏移量知道哪些数据要增量复制给从服务器。
问题又来了,缓冲区不可能一直存着数据吧?时间久了溢出怎么办?
其实这个缓冲区默认只有1M大小。当缓冲区写满后,主服务器继续写入的话,就会覆盖之前的数据
那么在网络恢复时,如果从服务器想读的数据已经被覆盖了,主服务器就会采用全量同步,这个方式比增量同步的性能损耗要大很多。
为了尽可能得避免全量复制,应该把这个缓冲区设置地大一点。
具体大小可以根据这个式子得到:

- second 为从服务器断线后重新连接上主服务器所需的平均 时间(以秒计算)。
- write_size_per_second 则是主服务器平均每秒产生的写命令数据量大小。
举个例子,如果主服务器平均每秒产生 1 MB 的写命令,而从服务器断线之后平均要 5 秒才能重新连接主服务器。 那么 repl_backlog_buffer 大小就不能低于 5 MB,否则新写地命令就会覆盖旧数据了。 当然,为了应对一些突发的情况,可以将 repl_backlog_buffer 的大小设置为此基础上的 2 倍,也就是 10 MB。